
北京大学宋洁教授团队在Cell Press交叉学科期刊Nexus发表题为“Bridging Prediction and Decision: Advances and Challenges in Data-Driven Optimization”的观点性综述文章,探讨了数据驱动优化方法在预测与决策领域的应用,系统研究了序贯优化(Sequential Optimization)、端到端学习(End-to-End Learning)和直接学习(Direct Learning)三种数据驱动优化方法的理论基础、优势及最新进展,并结合能源调度、运筹管理和智能控制等典型应用场景进行深入分析。通过剖析数据质量、优化建模和决策应用等关键问题,论文提出相应解决方案,旨在为复杂数据环境下的优化决策提供系统性的理论指导与实践参考。

研究背景
在大数据时代,数据规模的指数级增长为各行业的智能决策开辟了前所未有的新局面。“预测+决策”框架作为人工智能与系统科学相结合的重要手段,旨在从大规模数据中挖掘可泛化模式,从而为行业内的优化问题提供高效且可靠的决策支持。相比于传统确定性模型,数据驱动优化在应对复杂性与不确定性、提升灵活性与适应性以及增强泛化能力方面表现出明显优势。以能源系统为例,多时空尺度预测技术在电力经济调度中的应用,通过精准预测太阳能、风能波动及用电负荷趋势,优化可调资源、保障供需平衡,提高系统稳定性和经济性。
随着机器学习和深度学习技术的飞速发展,人工模型的表达能力得到了前所未有的提升,如何更具针对性地衔接好预测与决策的关系,成为提升系统效能的核心挑战,也是最终实现大数据价值转化的关键途径。本文从理论、应用、挑战和解决方案四个维度深入分析数据驱动的优化方法,旨在为行业提供理论框架与应用实践相结合的指导依据。
核心内容
预测与决策衔接框架主要分为三类,如图1所示。其中第一种为序贯优化(Sequential Optimization),该方法采用两阶段流程:首先利用预测模型对不确定因素进行估计,再将预测结果输入优化模块生成决策。此方法直观且模块化,各环节可独立优化,实现人工智能与决策模型的直接耦合。但由于预测目标与决策目标不一致,可能引发理论性偏差,从而影响整体决精度。例如,在可再生能源预测中,不同方向的预测误差(偏高或偏低)对电力调度产生的影响截然不同(如冷启动或电力消纳问题),即使相同幅度的预测误差也会对应不同的决策收益。这主要是由于优化模型的成本与约束具有非对称、非线性和动态的特性,使得降低预测误差不能直接转化为决策性能的提升。结果即便预测模型在统计意义上表现良好,其输出用于决策时仍可能偏离真正的最优方案。
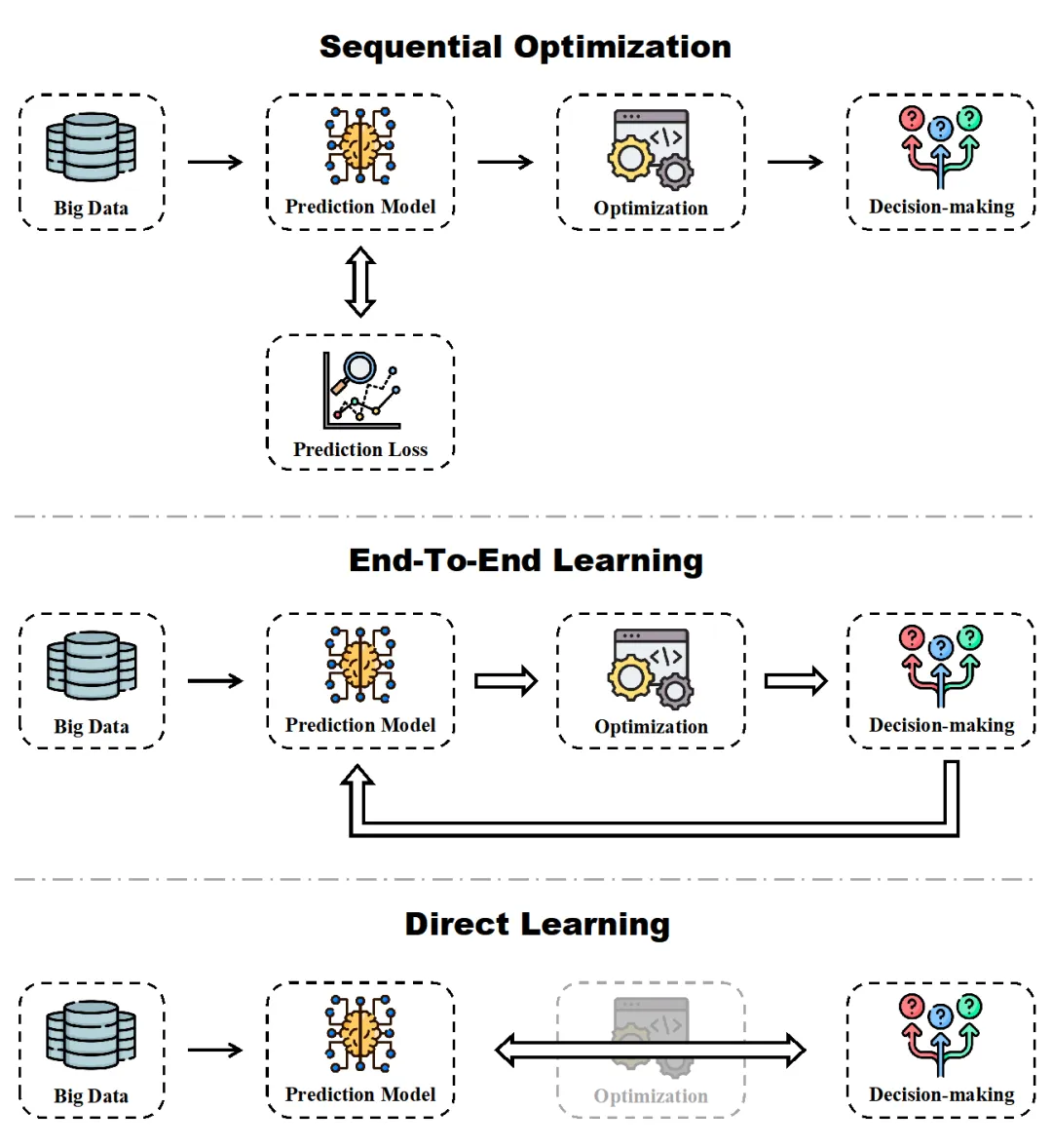
图1 衔接预测-决策的框架
第二种为端到端学习(End-to-End Learning),也称为决策驱动学习(Decision-focused Learning)。该方法将优化结构嵌入训练过程中,通过决策反馈直接调整预测模型,实现从预测到决策的闭环学习,从而更好地对齐预测与决策目标,减少传统两阶段方法中存在的偏差。但其实现更为复杂,对计算资源和梯度传播稳定性要求较高。如图2所示,由于带约束优化问题的非显式解,使得预测结果对决策的影响难以直接推导梯度,从而阻碍了端到端训练。为了解决这一难题,目前主要采用隐式微分法、代理变量法和近似梯度法,这些方法分别从不同理论框架出发,实现了带约束优化问题中梯度的计算,通过将决策损失反馈用于预测模型训练。相关方法已在能源调度和运营管理等领域得到成功应用:在电网调度中,采用隐式梯度和深度学习技术实现最优潮流及多能系统的智能调度,有效降低拥堵风险和运营成本;而在运营管理中,通过端到端决策驱动模型整合订单分配、路径优化与库存管理,显著提升整体运营效率和经济效益。
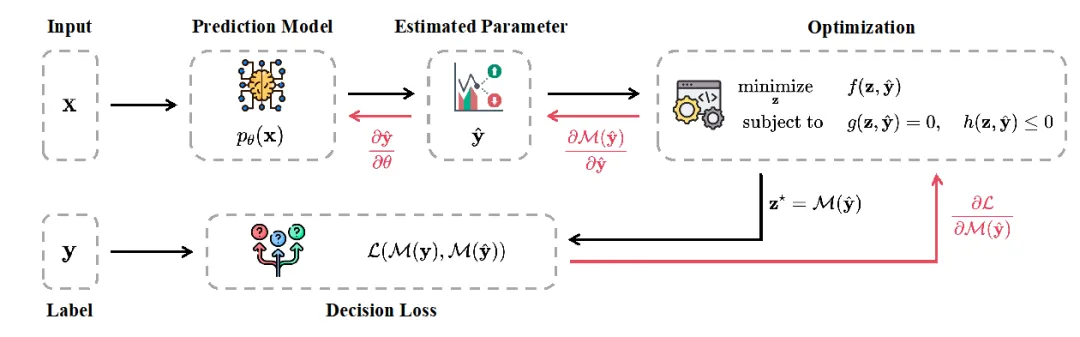
图2 端到端学习的梯度传递
第三种方法为直接学习(Direct Learning),主要适用于那些优化问题结构复杂或隐式表达的场景。该方法通过直接从数据中学习决策策略,并结合模仿学习或强化学习技术,使得系统能够自适应动态环境,在难以明确定义优化过程时表现出卓越的适应性和灵活性。相关研究在智能自主控制领域已取得显著成果,例如在自动驾驶、无人机控制和机器人等应用中,不仅实现了实时决策,还显著提升了系统的鲁棒性和运行效率。然而,直接学习方法通常依赖于大量专家标注数据,并且在稳定性和泛化能力方面仍面临一定挑战。三种数据驱动优化框架的相关特点及其适用领域的总结如表1所示。
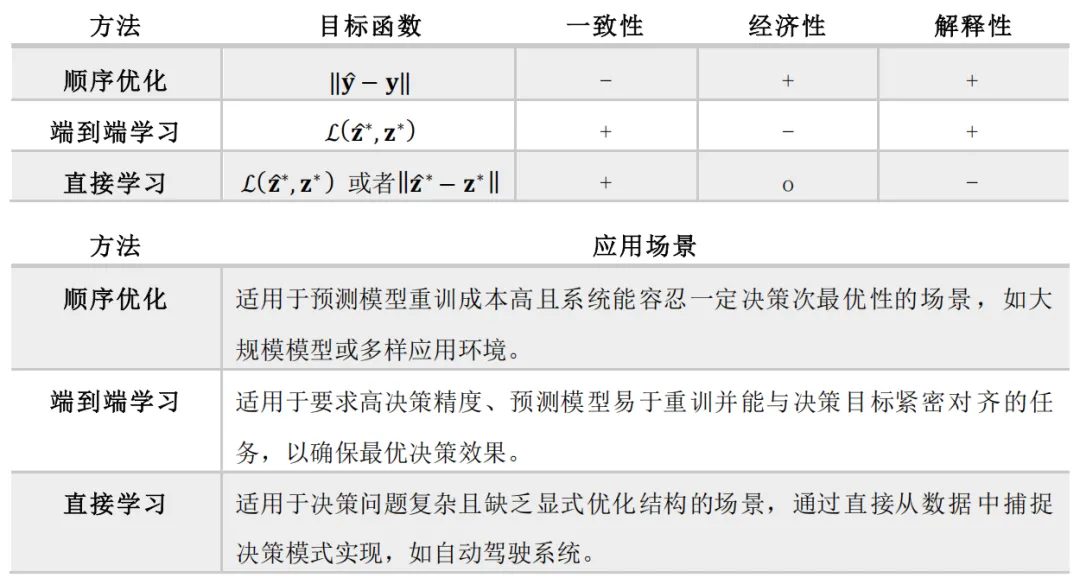
表1 不同数据驱动优化方法的比较
针对数据驱动优化理论在行业应用,本文从“数据质量–建模优化–决策应用”的全流程分析挑战并提出相应技术性解决方案,如图3所示。首先,数据质量是决策效果的基础,通过高效预处理和精准评估筛选出高价值数据,可显著提升预测精度和决策性能;其次,合理控制数据维度既防止模型过拟合,又降低训练成本。在优化建模阶段,不确定性建模至关重要,借助随机优化、鲁棒优化和分布鲁棒优化等方法可充分捕捉系统固有的不确定性,但这也增加了原有梯度解析的难度。同时,确保基于预测生成的决策在实际应用中满足约束条件十分关键,可通过高罚代价和后处理校正等策略保障决策的可行性。此外,增强模型的可解释性有助于建立信任和深入理解决策过程,采用特征重要性、LIME、SHAP等技术可使决策过程更加透明。最后,通过迁移学习和在线学习实现模型快速适应,确保系统在动态环境下具备良好的可扩展性,从而全面提升数据驱动优化的整体效能。
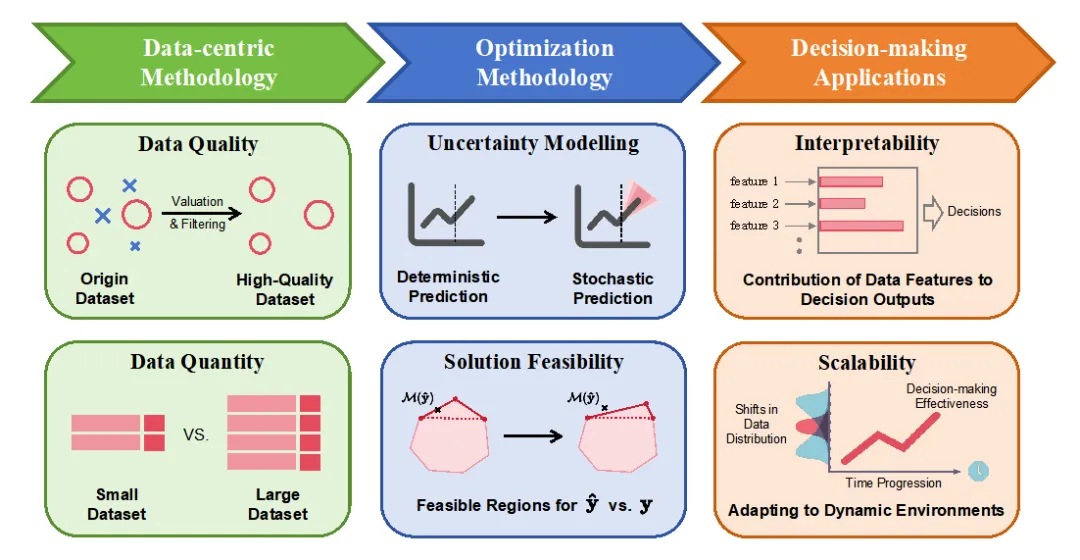
图3 实际应用中的挑战
论文总结
本文聚焦于数据驱动优化理论,系统综述了序贯优化、端到端学习及直接学习三大关键方法的理论基础、优势、最新进展与局限性,并重点介绍了它们在能源调度、运营管理和智能自主控制等领域的实际应用。文章对上述方法进行了多维比较,并深入探讨了数据驱动方法、优化建模与决策应用等环节所面临的关键挑战。本文旨在为学术界和产业界提供一份系统化的方法论指南,并展望在复杂数据环境下提升决策水平的未来发展方向。
研究团队介绍
论文第一作者为北京大学王衍之博士,北京大学大数据分析与应用技术国家工程实验室王剑晓副研究员和北京大学工学院党委书记、大数据分析与应用技术国家工程实验室核心成员宋洁教授是本文共同通讯作者。

OnePage

扫码二维码阅读全文
▌论文标题:
Bridging Prediction and Decision: Advances and Challenges in Data-Driven Optimization
▌DOI:
https://doi.org/10.1016/j.ynexs.2025.100057
转载本网文章请注明出处

