
2022年3月5日,由北京大学大数据分析与应用技术国家工程实验室、北京大学重庆大数据研究院共同举办的2022年第一届数智青年论坛顺利举行。论坛通过Bilibili在线直播,吸引了近千人观看和互动。数智青年论坛旨在广邀海内外优秀青年学者分享在大数据智能化、人工智能领域的相关研究成果与经验,增进学术交流,洽谈科研合作,推动人才引进与建设。
论坛由北京大学大数据分析与应用技术国家工程实验室数据预处理及统计分析中心主任、北京大学生物统计系主任、北京大学讲席教授、北京大学重庆大数据研究院副院长周晓华教授和北京国际数学研究中心长聘副教授董彬主持。北京大学数学科学学院党委书记、教授,北京大学重庆大数据研究院院长胡俊教授和北京大学数学科学学院教授、北京大学大数据分析与应用技术国家工程实验室副主任杨超教授分别致辞。

周晓华教授主持

董彬教授主持
 胡俊教授在致辞中表示,北京大学重庆大数据研究院的成立顺应时代潮流,符合国家战略发展需求,在成渝双城经济圈的发展中,重庆作为西部唯一直辖市,是成渝经济圈的中心城市,具有极其重要的战略地位,而“东数西算”也将会给重庆数字经济的发展带来重大机遇。随后,他详细介绍了北京大学重庆大数据研究院的组织架构、使命宗旨以及研究院成立以来取得的成绩。“燕园赴远添秋色,渝水迎新展笑颜。赓续传承先辈志,牛奔虎跃祭轩辕。”最后,胡俊教授以自创的一首诗作为结尾,激励各位科研工作者继承先辈遗志,在人工智能、大数据和数字化转型的科学研究和技术发展中留下自己浓墨重彩的一笔。
胡俊教授在致辞中表示,北京大学重庆大数据研究院的成立顺应时代潮流,符合国家战略发展需求,在成渝双城经济圈的发展中,重庆作为西部唯一直辖市,是成渝经济圈的中心城市,具有极其重要的战略地位,而“东数西算”也将会给重庆数字经济的发展带来重大机遇。随后,他详细介绍了北京大学重庆大数据研究院的组织架构、使命宗旨以及研究院成立以来取得的成绩。“燕园赴远添秋色,渝水迎新展笑颜。赓续传承先辈志,牛奔虎跃祭轩辕。”最后,胡俊教授以自创的一首诗作为结尾,激励各位科研工作者继承先辈遗志,在人工智能、大数据和数字化转型的科学研究和技术发展中留下自己浓墨重彩的一笔。

胡俊教授致辞
杨超教授在致辞中剖析了“数智”的深刻含义,出自《楚辞》:“数有所不及,智有所不用。”再多的数字也有表达不了的事物,再强的心智也有解决不了的问题。数字与智能相结合一定可以碰撞出激烈的火花,产生不可想象的力量。这正体现了数智青年论坛的主旨。同时,杨超教授还介绍到,北京大学大数据分析与应用技术国家工程实验室是在2017年经过国家发改委批复建设,由北京大学牵头,联合产学研多个单位共同建设的国家级科研平台,经过三年建设,实验室以优异的成绩在2020年通过了国家发改委委托教育部组织的验收。目前,实验室在校内已按照实体研究机构运行,并进入第二个非常重要的发展阶段。实验室的核心使命是发挥北京大学学科优势,吸引人才,建立团队,推进大数据、人工智能等核心领域的技术研发成果落地。

杨超教授致辞
致辞结束,八位来自海内外的优秀青年学者就大数据智能化、人工智能等领域的相关研究成果与经验作主题报告。
牛津大学张宇

张宇在《A Framework for Authoring Interactive Machine Learning Systems》报告中提出,交互式机器学习系统可以结合人与机器的长处协同解决问题。在完全依赖人工时过于耗力而昂贵、而完全依赖机器时不准确不可信的应用场景中,这些系统尤其重要。虽然交互式机器学习系统有许多优点,并得到了许多现实应用,但是其开发与评估中有各种挑战。这些系统的开发通常要求软件工程师有多领域的知识。这些系统的评估通常需要用户实验,因此评估较为昂贵和低效。通过对人机交互(HCI)和可视化(VIS)领域的研究,张宇提出了一组开发、应用以及评估交互式机器学习系统的方法。
圣路易斯华盛顿大学奥林商学院邱韫哲

邱韫哲在主题报告《Data-Driven Agriculture Network Optimization: A Predictive Prescriptive Dynamic Programming Approach》中讲到,本研究来自孟山都公司加拿大大豆供应网络优化。在这个供应网络中,公司决定从哪些农场采购以及采购多少,为整个销售季节准备初始库存,并对依次到达经销商的随机订单做出反应。利用数据驱动的预测规范性方法,将动态在线分配问题转化为线性规划,再建立不同模型求解库存部署问题。
荷兰莱顿大学医学中心陈煦
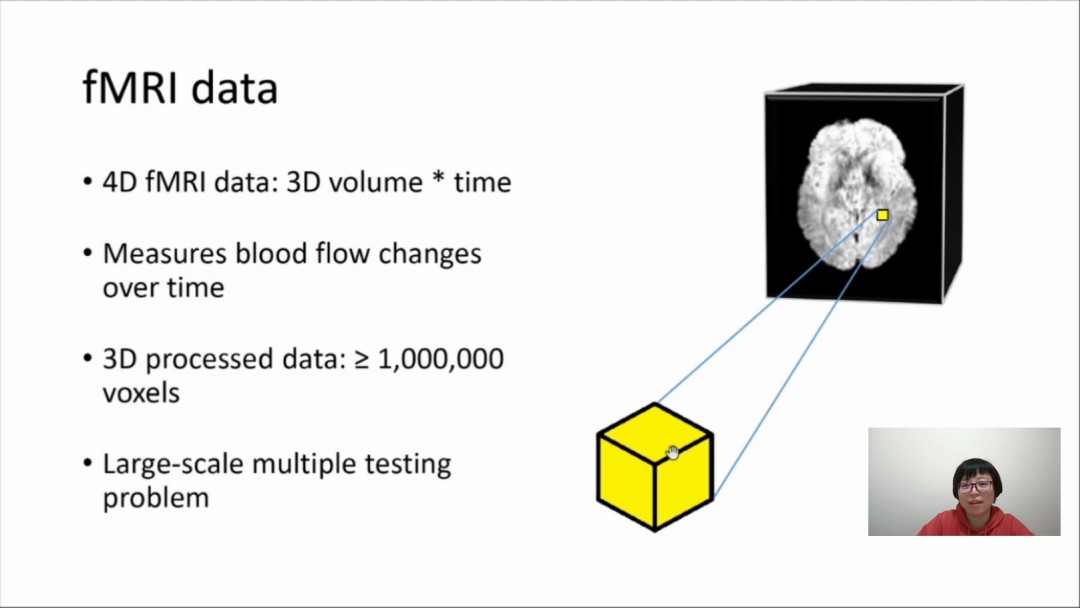
陈煦在报告《Improving cluster inference in neuroimaging data analysis using closed testing procedure》中讲到,经典的聚类分析在近年已经逐渐成为脑科学数据分析的标准方法。但是,该方法包含着一些众所周知的问题:可能导致过高的整体型I类错误,以及通常有着较低的空间特异性而无法很好的定位反应区域。对此,可考虑使用封闭检定法,该方法已被理论证明是控制整体型I类错误的最优方法,但对脑科学相关的大规模多重检验问题面临着巨大的运算量。为此,陈煦构建了相关的解决策略,并在实际应用中实现了多个线性和近乎线性时间复杂度的快捷算法。
南京大学大气科学学院王乐毅

王乐毅在《深度学习在台风边界层参数化方案中的应用》报告中讲到,常用的边界层参数化方案并不适合热带气旋数值模拟。而近期机器学习的兴起给改进它们提供了新的可能。王乐毅提出了一个全新的基于深度学习的边界层参数化方案。它的训练数据来自于理想热带气旋的大涡模拟,训练目标是边界层中的湍流通量。该方案拥有卷积网络结构,可以大大减少模型参数数量,让学习更加容易。在测试集上,该方案实现了比全连接网络更低的预报误差,而且比传统的YSU参数化方案得到的结果更好。为缓解原训练数据的不平衡性问题,进一步提出非线性变换方法作用于湍流通量数据,有效降低了模型对湍流通量的预报误差。
北京国际数学研究中心吴鹏

吴鹏在报告《Causual Inference in Recommender System》中讲到,当前,双稳健估计是推荐中表现最好的纠偏方法。然而,通过理论分析表明,双稳健估计依然可能具有较差的泛化能力,这种情况在实际中经常发生。基于此,吴鹏提出了一个新的双稳健估计的框架,并开发了两种具有更好泛化能力的双稳健方法。此外,双稳健方法依赖于倾向性得分和误差模型的估计,只要这二者中有一个估计不好,就会导致最终模型预测精度迅速下降。为了减少对这两个估计的依赖,提出了一种多稳健估计方法,并给出了其理论性质。
鹏城实验室唐科军

鹏城实验室唐科军在《DAS:A deep adaptive sampling method for solving partial differential equations》报告中介绍了一种求解偏微分方程(PDE)的深度自适应采样(DAS)方法,该方法需要两个深度模型,一个用于逼近偏微分方程的解,另一个用来指导生成训练所需的采样点。DAS整个方法流程包括两个部分:通过最小化训练集中采样点上的残差来求解偏微分方程,然后根据当前残差生成新的训练集以进一步提高当前近似解的精度。与均匀采样的神经网络近似相比,DAS可以显著提高精度,尤其是对于低正则性问题和高维问题。理论分析表明,所提出的DAS方法可以减小误差界,并通过数值实验证明了其有效性。
商汤科技研究院李秀红

李秀红在报告《深度学习中的计算和编译问题探讨》中讲到,随着深度学习被广泛应用于越来越多的领域中,深度学习模型中除了传统的卷积和矩阵乘法运算之外,引入了更多的新型算子,这些领域相关计算往往包含不规则计算,对模型表达、训练和推理带来了非常多的挑战;另外一方面,随着人工智能市场规模不断增加,新型芯片公司如雨后春笋,如何快速适配这些新型芯片也是一个新的挑战。本报告自上而下探讨从计算到芯片中的深度学习编译问题。
华为诺亚方舟实验室黄维然
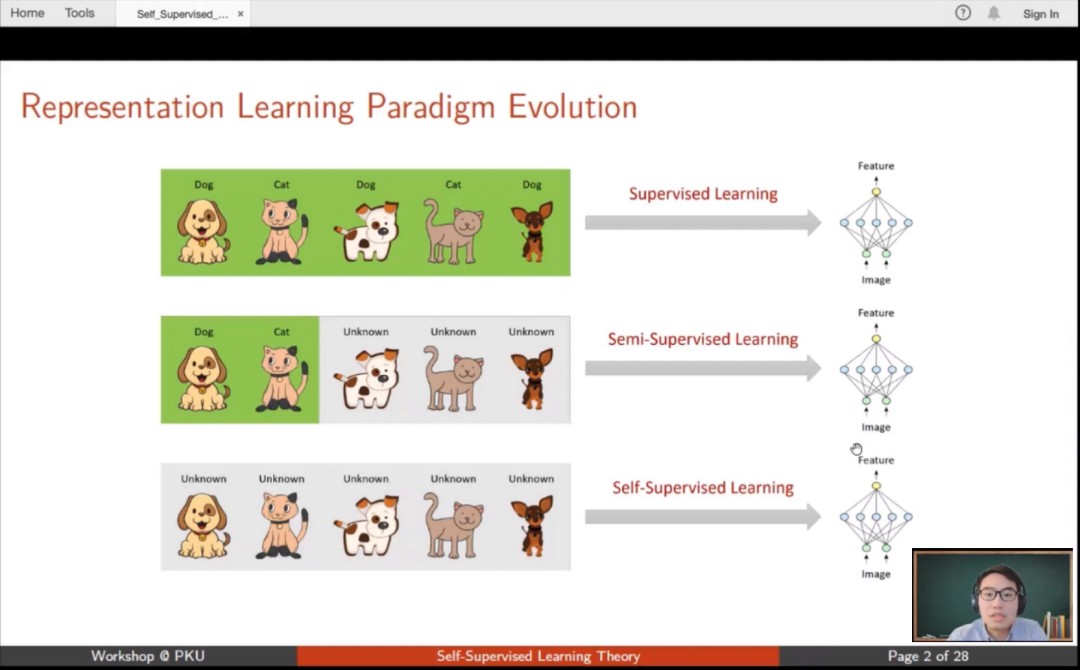
黄维然在报告《自监督学习理论》中讲到,自监督学习是利用大量无标注数据来做表示学习的一种学习范式,因其无需标注数据就能训练出与监督学习相当的性能而获得了广泛的关注。然而,自监督学习的各种算法在下游任务的泛化能力目前还没有很好的理论理解。黄维然从理论上分别分析了基于对比的自监督学习和基于代理的自监督学习,深入讨论了提升对比学习泛化性和提升自监督学习性能的一些关键技术和手段。,并提出了自监督理论未来的三个方向。
论坛报告结束后,报告人就报告内容和研究成果进行了热烈的交流和讨论。
未来,数智青年论坛将持续开展线上论坛,分享当前国内外大数据智能化、人工智能领域的最新研究成果、交流学术前沿热点、探讨学科未来发展趋势。我们诚挚邀请海内外优秀人才持续关注并加盟数智青年论坛。
转载本网文章请注明出处

