本文由科学大院根据中国科学院院士、北京大学讲席教授、大数据分析与应用技术国家工程实验室主任、北京大学国际机器学习研究中心主任、北京科学智能研究院院长、北京大数据研究院院长鄂维南院士在中国科学院学部第九届学术年会上的报告《数学与人工智能》整理而成,首发于科学大院。
人工智能是一个快速发展的领域,每个人都在以自己的方式体验它,每个人都有不同的感受和对未来的预见。
毫无疑问,计算机科学家是推动当前人工智能最前沿发展的主力。但早在1956年(即我们通常认为的“人工智能元年”)前,数学家们就已经开始系统地研究人工智能。
以四位数学家为例:
图灵(Alan Mathison Turing)是普林斯顿大学数学系的毕业生,研究数理逻辑,他的贡献无需多言;冯·诺依曼(Von Neumann)研究决策过程,这也是人工智能很重要的一部分;维纳(Norbert Wiener)从行为主义和反馈的角度来研究人工智能,而且他的研究非常系统,并不是零星的想法;香农(Claude Elwood Shannon)从通讯和信息理论的角度对人工智能进行了研究。
人工智能取得的辉煌成就
2012年以来,我们都能感受到人工智能取得的辉煌成就。2016年,AlphaGo战胜了当时最好的围棋选手李世石。
2024年,Alpha Geometry在奥林匹克数学竞赛平面几何的题目上打败了银牌选手,得分也远远超过了过去的最高水平。需要强调一下,过去的最高水平是吴文俊先生的解题方法。由此我们可以感受到,人工智能的水平跟我们最好的选手已经不相上下了。
ChatGPT和 GPT-4的水平怎么样?我举一个例子:“计算一根棒子的温度分布”这个题目并不难(见下图),但GPT-4的解题方法让我感到很震惊:它先写出微分方程,再加入边界条件,然后解微分方程得出了结果。这其实和我的做法差不多,这让我感受到了很大的挑战。

Sora可以生成视频,支持用简单的文本提示生成非常逼真的视频,这可以说是开启了物理世界跟虚拟世界连接的桥梁。

谈到AI for Science,AlphaFold2用非常简洁优雅的办法,把生命科学中一个非常基础的问题(预测蛋白质结构)彻底解决了,这是我们没有预料到的。我们正在做的OpenLAM,目的是发展一个通用的大原子模型。

现有人工智能技术路线不适合中国
除了以上的例子,我还可以用几个数字来告诉大家,Open AI公司有多么雄心勃勃。虽然其中一些数据不是经官方发布的,但从这些数字我们可以窥视到Open AI在人工智能领域的决心与野心。
到2028年,OpenAI和微软联合投资1000亿美元,打造“星际之门”算力系统。到2030年,他们计划耗费全球3%的用电量。另外,OpenAI准备筹集7万亿美元来建立新的芯片制造体系。这7万亿相当于去年的全球GDP的7%,而去年全球半导体行业的产值是5000亿美元,所以这个差距还是相当大的。大家都会好奇,这7万亿美元究竟要用于什么,因为整个芯片行业并不需要这么多钱。
然而,我想强调的是,这条技术路线并不适合中国,也不应该是未来人工智能发展的最佳路径。
理由非常简单:从国内的大模型顶尖团队来看,目前第一梯队的计算能力可能达到“万卡”的规模,比如1万张A100或者1万张华为910B的规模。到了明年这个时候,当GPT-5推出时,美国的第一梯队将拥有10万张卡的规模。10万张卡意味着什么?用人民币计算大约需要200亿到300亿元。那么,国内有多少团队能负担得起这样的花销?
另外,刚才提到的“星际之门”计划,投资大约1000亿美元,预计将使用百万张卡。百万张卡的能源消耗据说需要10个核电站来支撑,所以即便对于美国来说,负担这个项目也是非常不容易的事。这其中存在着巨大的能源问题和水资源问题。有人计算过,百万张卡的规模需要耗费英国一半的用水量来进行冷却。
而且,这样的技术路径本身存在巨大的浪费问题。
就中国来讲,我们在人工智能领域里面不光存在算力的问题,还存在着其他问题。
第一,我们的人才资源和算力资源没有对接好。我国当前的第一梯队是基于过去的人才体系建立的。而相比之下,Open AI的人才厚度和广度则完全不同。我们需要怎样的人工智能人才?他们不仅仅来自计算机视觉、自然语言处理、机器学习这些显而易见的领域,还应该来自更上游的算力系统、系统软件、高性能计算、数据库等领域,甚至于脑科学、心理学、物理学、数学等更广泛的领域。人才的厚度和广度极其重要,而目前我们国家有多少团队具备这样的人才储备呢?当前这些人才资源主要来自于高校,但实际上大多数高校在当前人工智能发展的前沿已经被边缘化了,这不仅是中国的情况,美国同样如此。我个人认为,中国人工智能发展的首要目标之一是要把人才资源和算力资源对接好。
第二,我们尚未建立好底层创新体系。当前的技术框架基本依赖于国外,我个人认为,我们还不具备一个系统的、完整的底层创新体系。
第三,我们还缺乏综合性、前瞻性的人才。
因此,我们现在面临两个基本任务:
一、要建立完整的人工智能底层创新体系,包括芯片、系统软件、数据和数据库、高性能计算等。这一底层创新体系必须建立起来,不能有任何幻想。
二、技术路线的可持续性问题也需要解决。新的技术路线从何而来?这需要我们不断探索人工智能发展的底层逻辑和基本原理才能找到。这是一个非常困难的任务,但必须直接面对。
探索底层逻辑和基本原理
人工智能发展的历史经历了多次大起大落,以及不断的“小起小落”。为什么会出现这种情况呢?其实,这是因为我们对人工智能的基本原理和底层逻辑理解不够透彻。
我最近在阅读《钱学森传》,发现钱学森在开展航天工作时,对未来3年、5年、10年都进行了非常好的规划,并且基本上是按照这些规划执行的。相比之下,人工智能领域连对下一年的发展都无法准确规划,原因就是我们缺乏对底层逻辑和基本原则的深刻理解。近年来人工智能不断超越我们的预期。这一现象既是好事,也有负面影响,因为我们无法准确预期和规划未来的发展。
我们可以根据三条线索来探寻人工智能的基本原理:
1.类脑的观点
人类的大脑,甚至一些动物的大脑,都是典型的智能系统。从这些系统中,我们学到了神经元、神经网络的概念。虽然以下问题一直没有完全弄清楚:人脑的概念是如何形成的?意识是如何产生的?直观感知的来源是什么?但从人脑研究人工智能必然会成为未来5至10年的一个重要研究方向。
2. 计算系统的观点
计算系统是一个非常典型的应用场景,当前的计算系统已经成熟,但人工智能代表计算的下一步——智能计算。
3. 数学的观点
比方说,我们需要为学习过程中的数据空间和物理世界建立数学模型。当我们谈论智能时,就必须为物理世界和机器人的物理操作建立数学模型。我还要提一下的是“心智空间”(mental space),虽然听上去有点像算命的术语,但实际上这是心理学领域的概念。现阶段对心智空间的心理学研究基本停留在描述性和概念性层面,但由于大模型的出现,我们现在有了实验工具,这是一个非常有前景的研究方向。从数学的角度,我们需要为这类研究建立相应的数学模型。
人工智能的主要技术
由于时间关系,我从数据的角度来介绍人工智能的主要技术,包括0数据、小数据、大数据、全数据。

1.0数据
0数据,即不需要用数据,主要技术是符号表示、逻辑推理,机器证明。1956年在达特茅斯第一次人工智能会议上,艾伦·纽厄尔(Allen Newell)和赫伯特·西蒙(Herbert Simon)就开发了Logic Theorist系统。该系统模仿了人类的思维方式和逻辑推理过程,能够证明一些简单的定理。这种技术路径虽然不需要数据,但总体上是模仿人的思维方式。
另外一种不需要数据的方法是专家系统。1997年,IBM开发的国际象棋电脑Deep Blue,就是一个基于专家知识的系统,它战胜了国际象棋世界冠军卡斯帕罗夫。然而,面对围棋这类复杂系统时,专家系统暂时却显得力不从心,因为这一类复杂系统将带来组合爆炸的问题。
对比国际象棋和围棋的棋盘可以发现,从国际象棋的8×8棋盘,到围棋的19×19棋盘,可以组合的选择是呈指数型爆炸式增长的。因此,专家系统的套路在解决围棋的问题时就无能为力了。Deep Mind的创始人就是看了国际象棋比赛,才发现需要发展新的技术。

2.小数据
在神经网络兴起之前,统计学习(如支持向量机)、Perceptron(小型神经网络)等基于小数据的方法已经在模式识别等领域得到了广泛应用。
然而,小数据方法同样面临维数灾难和组合爆炸的挑战。在数学上,维数指自由度的个数,所谓“维数灾难”指的是问题的自由度太多,导致复杂性指数级增长。
为了解决这个问题,我们也采取了多种策略。例如,在模式识别中,用特征工程来简化问题;在统计学中,用广义线性模型从经验中寻找非线性函数的线性组合,以描述多个变量的非线性关系;在量子化学中,Hartree-Fock模型作为一种基本工具,通过将多变量函数近似为单变量函数的乘积,来解决维数灾难问题。尽管这种方法可能存在较大误差,但在量子化学中却是一种基本的工具。
可以说,对组合爆炸和维数灾难认识的不足是人工智能经历大起大落的根本原因。
作为1956年达特茅斯会议的组织者之一和图灵奖获得者,马文·明斯基(Marvin Minsky)曾在1971年乐观地预测,在未来3到8年内,人工智能模型将达到一般人类的智能水平。显然他的预言没有实现。
1973年,应用数学家詹姆斯·莱特希尔(James Lighthill)在其报告中指出,人工智能的现实成果与专家们的承诺之间存在巨大差距。这份报告引发了人工智能领域的一系列反驳,人们认为该报告可能不够公平合理。事实是,从那时起,英国和美国开始减少对人工智能研究的投入,这导致了人工智能发展的低谷。
3.大数据
十几年前,深度学习开始兴起,这是一种基于大数据和神经网络的方法。其关键事件是2012年辛顿团队赢得ImageNet比赛。神经网络是一个古老的概念,但现代的神经网络层数更多一些。事实上,多层神经网络并非2012年首次出现,在算法层面,深度学习使用的反向传播算法和随机梯度下降算法也都是已知的算法。随机梯度下降算法起源于20世纪50年代,而反向传播算法则是在80年代提出的。
辛顿团队成功的关键在于,它首次真正地训练好了神经网络,这得益于两个主要因素:一是高质量、大规模的数据集,如李飞飞牵头构建的ImageNet;二是强大的计算资源,如GPU。两个因素的组合能够把神经网络的潜力充分发挥出来。这其中,辛顿(Geoffrey Hinton)功不可没。他坚持了40年的深度学习研究,尽管许多人对他的路径持怀疑态度,但他的坚持最终得到了回报。
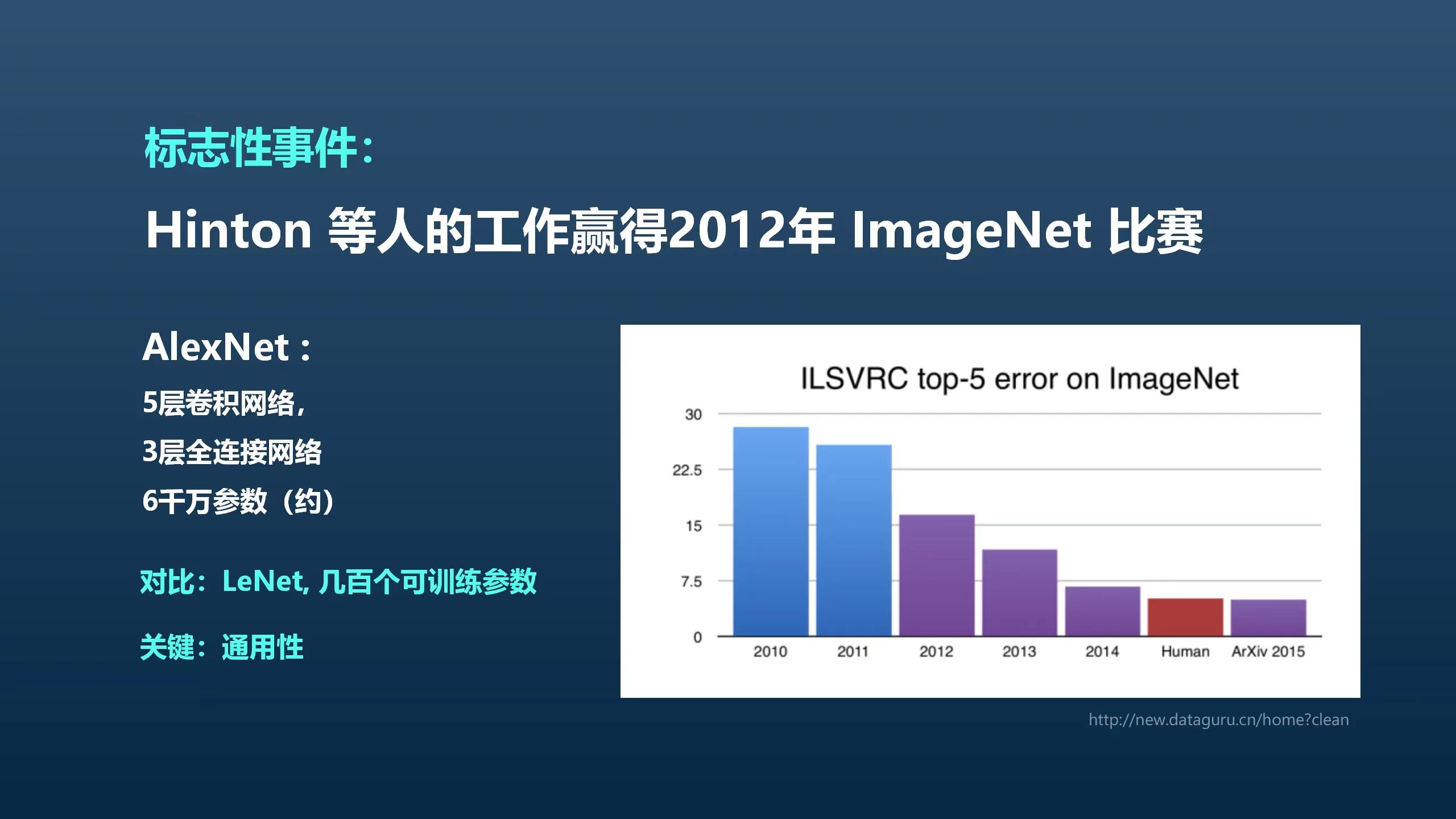
辛顿等人提出的AlexNet是一个由5层卷积层和3层全连接层组成的网络,拥有6000万个参数,这与之前用于识别手写数字的几万个可训练参数的LeNet网络相比,差距巨大。看到这个结果后,我的第一个想法是“或许我们能做得更好”。我甚至还和学生写了一篇文章,试图提出更好的技术路线。但后来发现这是徒劳的,因为我意识到,深度学习的方法不仅适用于图像识别,还具有通用性,可以用于其他任务,这也是现在深度学习如此广泛的原因。
如何用数学的观点来看待神经网络?
神经网络的概念可以追溯到20世纪40年代,是一项历史悠久的技术。直到60年代,明斯基和帕珀特(Seymour Papert)出版了著名的《Perceptrons》一书,希望为人工智能的发展建立一套基础理论。他们研究了哪些逻辑函数可以通过两层的感知机实现。但结论是悲观的:许多简单的函数都无法用神经网络来实现。这本书的出版对当时神经网络和人工智能的发展产生了非常负面的影响。我认为他们的出发点从根本上就是错误的。
进入80年代末,Cybenko定理的提出为神经网络领域带来了新的希望。这个定理证明了任何连续函数都可以用神经网络来逼近,许多人也将其视为神经网络最基本的数学定理。但这个观点也是错误的,数学家都知道,连续函数也可以用多项式来逼近,这被称为魏尔斯特拉斯逼近定理。尽管我们“玩转”多项式这么多年,但对于刚才提到的高维问题,多项式仍然有局限。Cybenko定理虽然正确,但并未明确指出神经网络与传统方法(如多项式)之间的本质区别。
1993年,Barron提出了一个真正的正确观点,他证明了神经网络逼近函数时,其收敛速度与维数无关。以多项式为例,要将误差降低10倍,所需的自由度数量需要指数级增长,这就产生了维数灾难。而神经网络则不受此限制,其性能与维数无关,这为我们提供了一个正确的出发点,突显了神经网络在处理高维问题上的优势。

在了解到Barron定理后,我意识到尽管这一理论没有得到足够的重视,但它为深度学习提供了重要的启示。首先,深度学习有潜力解决维数灾难问题,这正是我们在科学计算研究中所面临的主要困难;其次,我们需要从数学上更深入地理解深度学习与传统多项式方法之间的区别。基于这些认识,我着手布局了两个主要方向。这也是我投身于“AI for Science”的原因。
在科学领域,许多问题和困难都源于自由度过多,例如量子力学、分子动力学、蛋白质折叠等典型的多体问题。2018年,我和汤超院士在北大组织了一个讨论会,从那时起我们开始系统推进“AI for Science”。
当然,除了维数灾难问题,还有其他挑战,例如记忆灾难。在处理时间序列数据的时候,对记忆的依赖是一个主要问题。以侦探小说为例,故事的结局往往与开篇的场景紧密相关,但要处理这样长的记忆依赖是非常困难的。可以证明,传统的循环神经网络在这方面存在局限,而Transformer架构则没有这样的困难。
4. 全数据
刚才说的这些都是利用大数据,并且是具体场景下的大数据。接下去要谈到全数据,所谓全数据,就是如何把所有的数据都用起来。
在探讨如何充分利用所有数据的过程中,我们首先需要解决的关键问题是如何有效处理无标注数据。例如,对于医学影像数据,高质量的标注往往需要专业医生的参与,这在实际操作中难以实现。因此,大多数数据实际上是未标注的。为了解决这一问题,预训练模型成为了关键技术。目前,BERT和Open AI的预训练模型是两个主要的解决方案。BERT通过“填空”的方式进行预训练,而Open AI则通过“预测下一个词”的方式。

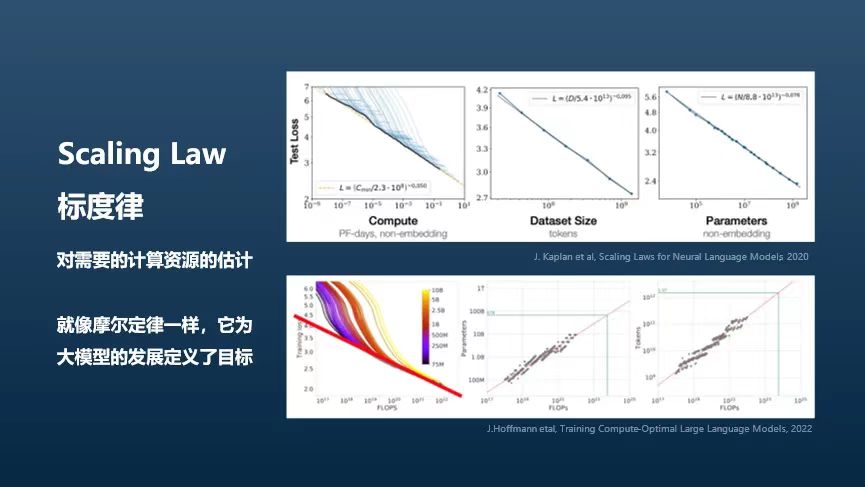
其次,我们需要考虑模型的通用性,即模型必须能够解决所有下游任务。Open AI的“预测下一个词”模型不仅具有通用性,还是一种生成模型,这与BERT有显著不同。更重要的是,这种模型具有标度律,这为我们提供了两个重要的好处。
首先,标度律可以帮助我们预测所需的计算资源。其次,类似于摩尔定律它可以作为指导我们对未来技术发展的目标。标度律是复杂系统的一个常见现象,它揭示了大尺度上系统行为的可预测性。
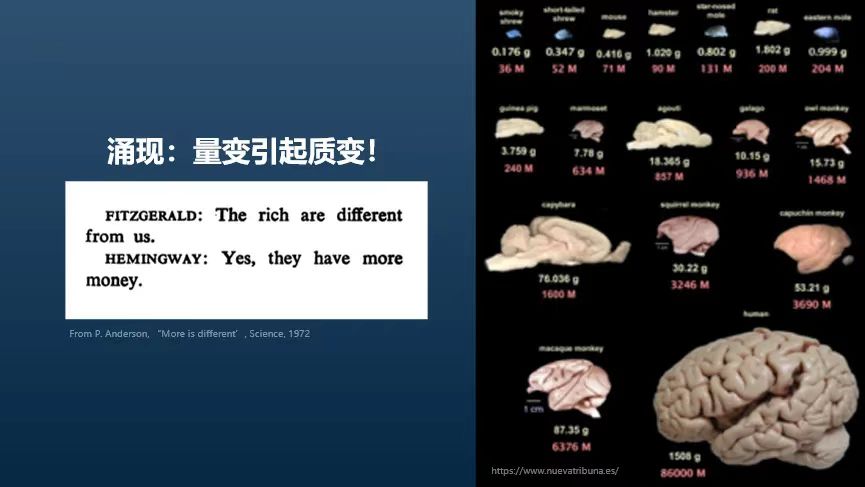
此外,我们有“涌现”的概念,即量变引起质变。以人类大脑为例,尽管我们的大脑结构与动物相似,但由于体积的差异,这种量变最终导致了质的飞跃。
如何降低大模型的计算成本
最后,我们来探讨一下如何从系统的层面降低大模型的计算成本。
人工智能有两个基本任务:一是要有知识,二是要有推理能力。
从知识的角度来说,知识可以被分为不同类型,包括极高频知识(如条件反射)、高频知识(如学习得来的数学知识),以及低频知识(如通过网络查询得到的信息)。这些知识需要不同的处理方法,但在此不作深入讨论。
从推理能力来说,有时需要严格推理,有时则可以相对宽松。以AlphaGeometry为例,它通过定理库实现严格推理,而直观的辅助线添加则来源于大数据模型。这种模式值得更广泛的推广。
但最重要的是,大模型开发不是“一锤子买卖”,而应视为整个系统的一部分,系统包括:底层的计算系统、算力、系统软件、数据库、模型、智能体和机器人,上层操作系统负责任务分配。这将是未来通用人工智能的正确发展框架。自2018年以来,我就开始布局这一领域,包括推动开发国际上第一个AI数据库。
当前,探索人工智能基本原理的时机已经成熟,与过去相比,现在我们拥有了所有必要的基本条件。这一探索不仅是人工智能长期发展的基础,也是确保其持续进步的关键,对中国而言,考虑到我们在某些资源方面有所不足,从基本原理出发制定技术路线尤为重要。此外,这一过程还需要多学科人才的紧密合作。
至于我国应该如何布局人工智能战略,我认为要从整个计算产业的角度来规划。高校作为人才培养的基地,需要认识到人工智能是一个特殊的学科,并从全校层面进行战略布局。最终目标是实现人力资源和算力资源的有效对接,构建一个高质量、多层次的人才梯队。
谢谢大家。
作者:鄂维南院士
文章来源:科学大院
转载本网文章请注明出处

