正文共7579字,预计阅读时间约为20分钟
(本文由科学大院根据北京大学大数据分析与应用技术国家工程实验室主任鄂维南院士在第204次科学与技术前沿论坛上的报告《The Science of AI》整理而成,首发于科学大院。)

鄂维南院士做报告
(图片来源:中国科学院理论物理研究所)
今天我报告的主题不是 AI for Science,而是 Science of AI。AI for Science,是利用人工智能来攻克科研中依赖经验和试错的问题;而Science of AI,则是以科学的方法体系来推动人工智能自身的发展。如果人工智能本身也依靠经验和试错作为主要发展模式,这将构成一个根本性的问题。所以,我们需要思考如何推动人工智能从工程化走向科学化。
人工智能的研究先驱
先回顾人工智能发展历史上的先驱者。在达特茅斯会议之前,人工智能的研究者以数学家为主,比如图灵(Alan Mathison Turing)、冯·诺伊曼(Von Neumann)、维纳(Norbert Wiener)、香农(Claude Elwood Shannon)等人,他们的工作集中于构建人工智能的理论与概念基础。会议之后,明斯基(Marvin Minsky)、麦卡锡(John McCarthy)、西蒙(Herbert Simon)和纽厄尔(Allen Newell)等人对人工智能的进一步发展起到了关键作用。
编者注:达特茅斯会议是1956年夏天在美国达特茅斯学院举行的一场具有历史性意义的研讨会,由麦卡锡等人发起,聚集了香农、明斯基等多位未来图灵奖得主,共同探讨用机器模拟人类智能的可能性。“人工智能”(Artificial Intelligence)这一术语在会议上首次提出。


人工智能的研究先驱。从左到右:
上:图灵、冯·诺伊曼、维纳、香农
下:明斯基、麦卡锡、西蒙、纽厄尔
达特茅斯会议之后,人工智能主要遵循一条工程化的路线发展,并且取得了巨大的成就,诞生了如 Lisp 语言、IBM “深蓝” (Deep Blue)、AlexNet、AlphaGo 等里程碑式的工程项目。相对而言,AI的基础理论研究是比较滞后的。这并不是因为没有人研究人工智能的基础理论,而是相关研究没有跟上人工智能发展的步伐。这里举两个例子:
一个例子是明斯基和派珀特(Seymour Papert)在1969年所写的一本书《感知器》(Perceptrons)。他们的出发点是探究人工智能的理论基础,但这本书的结论具有严重的误导性,对人工智能的后续研究方向造成了负面影响。
另一个例子是瓦普尼克 (Vladimir Naumovich Vapnik)的经典著作《统计学习理论》(The Nature of Statistical Learning Theory)。尽管这本书在统计学习领域影响深远,但没有涉及深度学习,还停留在机器学习的早期研究框架上。

左:《感知器》右:《统计学习理论》
基础理论缺失造成的后果是人工智能的发展经历了几次大起大落;几乎没有哪个学科像人工智能一样,发展历程一会迎来热潮,一会跌到低谷。同样,理论研究的缺失也直接导致了当下的大模型开发依然高度依赖经验与试错,门槛高、成本高、资源浪费的情况很严重。
人工智能的主要方法
从数据使用量的角度来看,人工智能的主要技术可以分为四类:0数据、小数据、大数据、全数据。
一、0数据
0数据,即不依赖数据,而依赖人工定义的规则与逻辑,主要技术路径是符号表示、逻辑推理、机器证明、专家系统等。0数据的一个典型例子是专家系统,它最具代表性的成就是1997年IBM的“深蓝”击败国际象棋冠军卡斯帕罗夫。
但是,专家系统的难题在于组合爆炸。尽管它可以处理8x8的国际象棋棋盘逻辑,但面对19x19的围棋棋盘,组合选择呈指数级增长,就会出现组合爆炸问题。哈萨比斯(Demis Hassabis)正是意识到专家系统的局限性,因此在深度学习出现之后看到了新的可能的路径,最终攻克了围棋难题。

二、小数据
小数据以经典的统计学习方法为代表,其特点是模型结构相对简单、样本量有限。这种技术主要面临的困难是维数灾难和组合爆炸。
维数灾难是指随着系统复杂性(例如自由度个数,或维数)增加,计算量呈指数级增长。众多学科领域中都存在维数灾难的问题。为此,科学家们不得不发明一些简单粗暴的近似方法来解决现实问题,如量子化学中的Hartree近似。为什么早期的人工智能领军人物(如西蒙和明斯基)对于人工智能的发展曾做出过于乐观的预测,主要原因之一是他们没有认识到,将解决简单问题的经验应用到复杂问题时,会碰到维数灾难之类的问题。
三、大数据
大数据最典型的例子就是深度学习。2012年,杰弗里·辛顿(Geoffrey Hinton)带领的团队凭借AlexNet赢得ImageNet竞赛,将错误率大幅降低了十几个百分点,这是深度学习崛起的标志性事件。尽管多层神经网络等算法早已存在,但只有在海量的高质量数据(例如 ImageNet)与算力资源(GPU)的共同支撑下,它的潜力才完全发挥出来。

辛顿对深度学习做出了巨大贡献。他早在博士论文期间就开始神经网络领域的研究,在无人看好的领域坚持数十年,最终引领了深度学习的爆发式发展。
四、全数据
当下的大模型都在强调“大”。其实“大”是次要的,最重要的是实现全量数据的有效利用。例如,GPT-3在发布时号称使用了当时互联网上所有文本数据。而要处理全量数据,模型就必须足够大。这需要解决两个技术问题:
1.预训练。核心目标在于如何高效利用无标注数据。
2.通用性。既然使用了全量数据,就必须具备解决所有下游任务的能力。
此前业界存在两条主流的大模型路径:谷歌的 BERT(基于掩码的填空式学习)和 OpenAI的GPT(预测下一个词)。最初谷歌的方法因为训练效率高而更受欢迎,但两者有一个本质区别:预测下一个词能以通用的表达方式解决翻译、对话、推理等各种语言任务,而“填空”模式并不能实现这一点。这也是为什么当时OpenAI在大模型竞争中占据了领先地位。
深度学习的基础理论
尽管深度学习在实践中取得了巨大的成功,但仍然存在许多基础理论问题尚未解决,充满了各种各样的未解之谜和“黑魔法”。例如:
为什么深度学习的效果优于其他机器学习方法?
为什么多层神经网络的训练如此困难?
为什么随机梯度下降(Stochastic Gradient Descent, SGD)的效果往往好于梯度下降(Gradient Descent,GD)?
为什么批标准化(Batch Normalization)能显著提高神经网络训练效果?
为什么循环神经网络难以处理记忆较长的序列?
……
我们能否对这些问题有基本的认识?这就需要研究深度学习的基础理论。
一、有监督学习
有监督学习是深度学习中的核心方法之一,其本质上是关于函数逼近的计算数学问题。例如在图像分类问题中,我们需要构建一个映射函数,图像是自变量,分类结果作为因变量。我们有有限个样本点上的函数值。我们的任务是利用这些信息得到一个目标函数的高精度逼近。下图展示了对CIFAR-10数据集中部分图像及其分类结果:

CIFAR-10数据集中的部分图像示例。
CIFAR-10数据集是一个广泛用于机器学习和计算机视觉算法的图像集合。它总共包含60000张32x32像素的彩色图像,分为10个不同的类别。
神经网络本质上可视为一类特殊的函数,就像多项式是另外一类特殊函数一样。从数学的角度来说,我们还可以从动力系统的视角来审视神经网络,反向传播算法等优化方法可以很自然地被理解为动力系统的基础算法。

二、维数灾难
对于函数逼近问题的研究,计算数学和深度学习的一个根本区别在于问题的维数。传统计算数学侧重于处理一维、二维等低维问题,十维就被视为很高的维度;而在图像分类任务中,每个像素都是一个自由度,一张32×32像素的彩色图片,自由度是32×32×3=3072,维数是三千多。从计算数学的角度,想处理这么高维数的问题几乎是无能无力的,但是深度学习却能较好处理。
为什么高维问题在计算数学中难以处理?根源在于经典逼近理论中的维数灾难。比如用分片线性函数逼近目标函数,假设需要m个网格点,每个网格的宽度是h,m和h之间有以下关系(d是维数):

分片线性函数逼近的误差是二阶的:

如果想将误差降低为原先的十分之一,网格点的个数需要增加10d/2倍;如果维数d=3000,那么网格点就要扩大到原先的101500倍,这是一个天文数字。这类维数灾难的问题不仅存在于分片线性函数逼近,在几乎所有的计算数学方法(比如小波方法、三角函数逼近)都普遍存在,所以非常难以解决。然而,深度学习似乎不存在维数灾难的问题。这是为什么?我们从一个经典的例子,高维积分的计算,来开始探讨这个问题。比如对于积分I(g),用Im(g)逼近:

如果使用传统的基于网格的方法,如梯形公式,那么误差的表达和分片线性函数是类似的,存在维数灾难:

但如果采用蒙特卡洛方法,误差中m的指数就不存在1/d的项,与维数无关,因此能够计算维数高达数百万的积分:

我们再从高维积分的角度出发,再来看函数逼近的问题。假如目标函数能够被写成如下形式,其中π是某个概率分布:

这就将函数逼近问题转化为积分问题,利用蒙特卡洛方法解决,逼近误差就不会出现维数灾难。
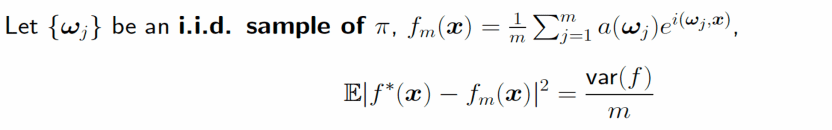
这里的关键是,上述逼近函数恰好是一个两层的神经网络,只不过其激活函数是指数函数:

所以说只要目标函数具有上面的积分表达形式,就可以使用两层的神经网络来逼近,同时逼近误差没有维数灾难。
在这一问题的启示下,我们可以定义一系列的函数空间,使得函数逼近的误差没有维数灾难。因为巴伦(Andrew R. Barron)是最早考虑相关思路的,我们把这类函数空间称为Barron空间。

当然,逼近误差只是一个因素。我们还需要考虑泛化误差、训练误差等。总之,这个问题还远远没有完全解决。但从上述分析,我们可以看到,深度学习方法对高维问题的效果的确跟经典方法不一样。
总结一下,我们应该如何用正确的数学观点看待神经网络?
之前提到,明斯基和派珀特在《感知器》中提出了一个误导性的看法。书中研究的核心是单层感知器,这可以看成是最简单形式的神经网络。他们的出发点是问这样一个问题:单层感知器可以精确表达什么样的逻辑函数?结果发现连最简单的逻辑函数都无法被精确表达,由此他们得出了非常悲观的结论。事实上,他们的出发点就是错误的:我们不应该追求精确表达函数,而是应该采用逼近论的观点来看待这个问题。
从逼近论的角度出发,西本科(George Cybenko)证明了所谓的通用逼近定理(Universal Approximation Theorem),即在闭区间上任何连续函数都可以用神经网络来逼近到任意精度。这的确是一个重要结果。但是,这一定理不能区别多项式和神经网络。数学专业的大一学生就学过魏尔施特拉斯逼近定理(Weierstrass Theorem),即在闭区间上任何连续函数都可以用多形式来逼近到任意精度。但是我们知道在高维空间,神经网络逼近和多项式逼近的表现非常不一样。正确的出发点应该是探讨逼近速度和维数的关系。前面关于Barron空间的结果是这个方向的一个起点。
认识到深度学习可能是解决维数灾难的一个有效工具,是一个巨大突破,因为许多问题的核心困难都是维数灾难,例如最优控制问题、高维微分方程等。我们推动AI for science最初的出发点也是如此,因为维数灾难是许多科学问题的核心困难,比如量子力学、分子动力学、蛋白结构等等。
三、深度灾难
深度神经网络在训练过程中会产生梯度爆炸或消失的现象,导致很难训练好比较深的神经网络。这个问题我们称为“深度灾难”。
大约十年前,训练多层的神经网络是一件非常困难的事情。这一难题后来由残差网络(ResNet)得以解决。
训练神经网络通常使用各种梯度下降的方法,所以避不开计算梯度,而梯度涉及到所有参数矩阵的连乘。由于神经网络在训练时一般是随机赋予初值,数学中著名的乘法遍历定理(multiplicative ergodic theorem)告诉我们,多个随机矩阵乘积得到的矩阵随着个数的增加会呈指数变化,这个指数的基数是一个被称之为李雅普诺夫指数的数字,通常记为κ。如果李雅普诺夫指数κ大于1,那么随着深度的增加,梯度是指数爆炸的;如果κ小于1,那么梯度是指数衰减的。两种情况都不是好结果。

解决的办法很简单:回到神经网络的动力系统定义,如果我们在右边加上一个项zk,且在切始化时将参数W取得很小,这个动力系统可以视为一个恒定动力系统加上一个小的扰动。此时,κ就会非常接近1,从而解决了梯度指数爆炸或消失的问题。这就是残差网络能够解决深度灾难的本质原因。

四、梯度下降和随机梯度下降,哪个更好?
从计算效率来看,随机梯度下降显著优于梯度下降,因为后者每次迭代都需要计算整个数据集的梯度,而随机梯度仅随机选取几个数据上的梯度,显然计算效率更高。那么,两种方法在测试误差上的表现如何呢?
十年前,有一个很著名的谜题:随机梯度下降不仅效率高,准确率也往往比梯度下降更好。这是一个普遍观察到的现象,尤其是在网络参数个数大于训练数据量的过参数化情形下(即变量个数大于方程个数),此时可以得到多个训练误差为0的解,不同的训练方法会收敛到不同的解。这自然引出一个问题:给定一个训练方法,它会选择哪个解?
我们还是从动力系统的角度来看这个问题。不过现在的动力系统不是神经网络,而是将训练方法看作一个动力系统,例如梯度下降、随机梯度下降。
动力系统中有一个非常基本的概念:动力系统的收敛解必须是线性稳定的。从动力系统稳定性的角度出发,我们可以分析随机梯度下降的线性稳定性。我们从一个简单的一维问题出发。下方表达式是线性化之后的随机梯度下降的迭代公式,其中Hj是第j个数据的海塞矩阵(Hessian Matrix),η是学习率(Learning Rate),B是批次大小(Batch Size)。集合中批次的选取是随机的,所以这是一个随机动力系统。

分析这个随机动力系统的稳定性,需要引入两个量:所有矩阵Hj的平均值,我们称之为尖锐度(sharpness);还有方差,我们称之为不均匀度(non-uniformity):
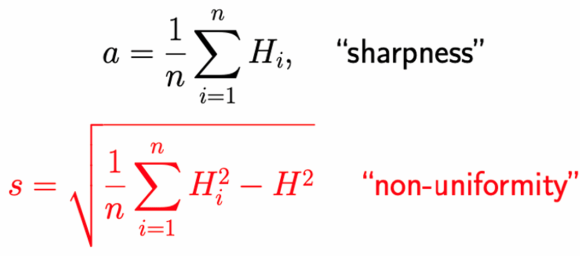
简单的分析可以给出稳定性条件:

在尖锐度和不均匀度组成的空间中,分别固定学习率(下图左)和批次大小(下图右),画出稳定性区域,会发现稳定性随学习率和批次大小发生变化,而且随机梯度下降的稳定性区域小于梯度下降的稳定性区域。

吴磊在实验中还发现了这样一个现象:当梯度下降的准确度接近100%时,如果突然把训练方法更换为随机梯度下降,那么训练的轨迹会快速逃逸原来的轨迹,然后再慢慢重新收敛,并收敛到另一个解。这个现象的原因就是梯度下降可以收敛到很多个解,但大多数这些解对于随机梯度下降都是不稳定的,后者只能在别的地方找到稳定的解。

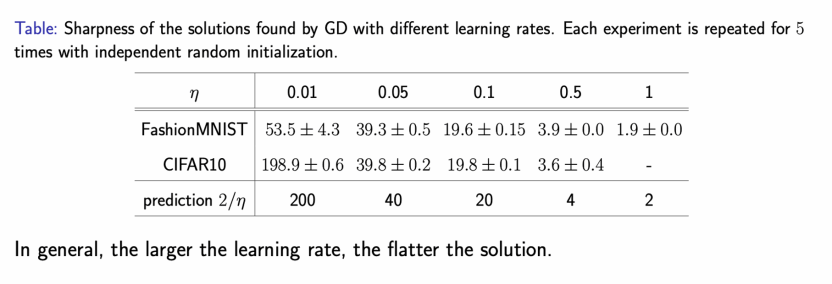
再看看实际计算中的情况。我们让梯度下降在两个数据集(Fashion-MNIST和CIFAR-10)上使用不同的学习率进行训练。梯度下降的稳定性要求表明,尖锐度必然小于2/η。从实验结果我们可以看出这个稳定性条件是满足的。更为重要的是,我们发现实验结果离稳定性的边界靠得很近,梯度下降方法的训练轨迹实际上是处在稳定区域的边缘(edge of stability)。随机梯度下降也有类似的现象。
5.序列问题与记忆灾难
如何基于一个已有序列,预测下一个词?这是大语言模型的核心问题。这类问题的难点在于记忆:比方说下一个词与前文多长区间的词存在依赖性?一个典型困难是“记忆灾难”:可以证明,如果关联的区间(也就是“记忆”)非常长,循环神经网络(RNN,Recurrent Neural Network)所需的神经元个数会随记忆区间长度的增加而呈指数级增长。

同时我们还证明了,Transformer架构在一定条件下不存在记忆灾难。事实上,这个理论告诉我们, Transformer架构能够有效处理复杂但稀疏的长记忆问题。这是大语言模型普遍转向Transformer架构的一个重要原因。
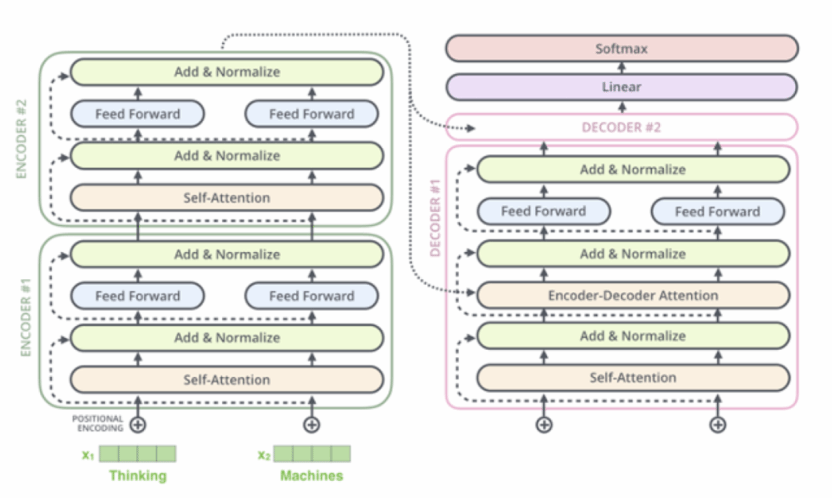
编者注:Transformer架构是由谷歌团队在2017年的里程碑式论文《Attention is All You Need》中提出的一种深度学习模型架构。与以往逐字解析序列的旧模型不同,它引入了“自注意力机制”(Self-Attention),使得模型能够像人类阅读一样,在处理一个词时同时“扫描”整个句子,自动捕捉词与词之间跨越长距离的逻辑联系。Transformer架构让机器在理解复杂上下文和语义关联上产生了质的飞跃,彻底改变了人工智能处理语言的方式,是当前ChatGPT等大语言模型的核心基石。
6.MoE(混合专家模型)架构
MoE架构在当下非常热门,基本原理是通过路由(Router)机制,将不同的任务分配给最擅长的“专家”(expert)。
从流形学习的角度来看,我们可以想象数据是分布在一个高维的“曲面”(即流形)上。由于流形通常没有统一的全局坐标,只能通过多个局部坐标片(patch)一起拼起来覆盖。每一个“专家”本质上就是在负责处理流形上的一个局部切片。
此外,从分片函数的视角来看,MoE架构就像是用许多小网络去拟合一个复杂的分片函数。其能够拟合的函数的片数随着网络层数的增加呈指数级增长,所以MoE架构是扩展模型容量的有效方法。

7.大语言模型
最简单的语言模型是N-gram,即用前N个词来预测下一个词。在长文本中,N可能很大,就像一本小说第一页的故事对于最后一页的情节可能都有影响。这意味着模型需要处理长程记忆,而这种记忆往往是稀疏的。Transformer架构的成功,恰恰在于它能够高效处理这种稀疏长程记忆。
然而,语言实际上不能用N-gram来建模,而是需要用“Hidden N-gram”,因为我们不会把所有想到的东西都说出来。例如在推理时,我们并不会写下所有的推理过程,正如数学家经常用“显而易见”来省去一些证明。语言的文字表象之下,隐藏着大量未表达的逻辑。
大语言模型推理的难点在于,随着隐藏的推理步数增加,推理难度(例如需要的数据量)呈超多项式增长 (super-polynomial growth)。我们称这种现象为推理步数灾难。这正是我们需要思维链(Chain of Thought, CoT)的原因——通过引导模型补充中间步骤,将隐藏的信息外显化,从而缩短隐藏步数,降低推理难度。
总体来说,深度学习是一个很清晰的数学问题,核心挑战在于高维、长程记忆等复杂任务的处理。而大模型更像一个复杂系统问题,需要处理各种复杂行为,所以更接近于统计物理的研究范式。
人工智能的系统论
如上所述,对于深度学习和大模型,我们其实已经积累了许多比较深入的理解。但为什么我们还总是觉得人工智能充满各种惊奇、奇怪、难以理解的事情?为什么我们对人工智能的发展没有可靠的预判和把控?这主要有两个原因:一是理论方面,仍然有许多基本问题没有解决,还没有形成一套基本原理可以作为指导原则;二是人工智能系统是一个包括许多核心组分的复杂系统。我们需要从系统的角度看待人工智能。
复杂系统的一个典型案例是飞机。飞机的设计从早期的工程化走向有严谨设计体系的科学化,乃至总结出一套基本原理式的指导原则,这中间经过了一个漫长过程,最后形成了一套系统论方法。对于这样一个复杂系统,我们需要定义系统的每一个部分,定义每个系统的设计目标,并完成整体优化。

人工智能不只是一个大模型,而是一个复杂系统。它包括:
内核:例如大模型;
内存:记忆系统;
外部接口:AI数据库等;
本体:软、硬智能体;
环境:物理环境、逻辑环境。
比如说,“忆立方”是较早从系统角度来设计的大模型,它最早提出将推理和记忆分离,实现记忆分层。通过将海量知识保存在内置知识库中,“忆立方”大幅降低了模型读写知识的成本。

从方法论的角度来看,我们还需要将基于数据的深度学习方法与经典的逻辑方法结合起来。AlphaGeometry模型就是一个这样的例子。在几何证明中通过大模型建议证明的策略(例如如何添加辅助线),再依据定理库给出逻辑证明。
总结与展望
总结主要有两点:
第一点,人工智能在理论层面已经取得了巨大进步,只是这些成果还没有被普遍了解。相信今天报告中的很多内容,即使是人工智能理论研究领域的从业人员也并不完全熟悉。
我们重点强调了人工智能发展历程中已经初步解决的几个“灾难”性困难:
人工智能仍有许多问题,其解决需要更深入的洞察力:例如如何以最优规则给大模型“喂数据”?生成式人工智能的不同方法如何统一起来?非结构化数据如何建模?预训练和后训练之间的关系是什么?这些问题都有待我们的思考。
第二点,我们已经到了可以推动人工智能从工程走向科学化的转折点。具体包括以下层面:
只有推动人工智能从工程化走向科学化,才能避免泡沫和不必要的起伏,保证人工智能的长期稳定发展。
谢谢大家。
作者:鄂维南院士
文章来源:科学大院
转载本网文章请注明出处

